Monolith. Divide or not divide.
Let's look into problems that arise when your monolithic web application grows. What happen when more functionality added:
- the application consumes too much hardware resources and is reaching the limits of one machine
- some components are less reliable than other and make the whole application unstable or unavailable
- high user load even on one component can slow down the whole application
- the application deployment becomes harder, more risky and less frequent due increased testing scope and deployment time
Running many application instances doesn't help much because they still consume a lot of resources, fail to start or run smoothly, and each instance has the same bugs and performance issues. The possible way to handle these issues and stay in the business is to divide the application into separate deployment units called services:
- deployed and started independently
- consume less resources that the whole application: memory, CPU, database connections etc.
- dependent on other services only within a workflow (user case) so the called services should be available within the workflow execution only
- the service workload doesn't affect other service performance, if they don't participate in same workflow
- a service performance can be adjusted independently by adding more service instances (scaled up individually) or using more powerful machine only for a high load service, instead the whole application. So extra costs are not spent on other services that don't require it.
Where to start: components
To start the issues isolation and reduce the testing scope, we divide our application code base into components:
- by directory structure or namespaces each component has clear component boundaries: it's responsible for specific application or infrastructure function
A modular application is a starting point. With clear component boundaries and how the components communicate to each other, you can tell:
- which components are involved into a user scenario
- where to find the component files
So can you find all places in the code that affect only specific scenarios and nothing else. That speed ups the development and makes the changes less risky.
What's next: separate deployment unit
The next step is to place components into services that could be deployed and run separately:
- each component is placed only into one service, its code is moved to the service folder
- change local calls to remote or asynchronous messages if the called function belongs to a component from other service
- specify service dependencies, required to start a service: third party libraries, database, event broker connections etc
There is no strict limitation to the services number, except each service should include whole components and at least one component. So the number of services can't exceed the components number. You can place several components into one service or even divide all components into two services. Typical scenarios to start:
- move critical functionality to a separate service so changes in other service won't affect this functionality. Example: there's a component that processes payment card payments and it doesn't change often so it makes sense from the business point of view to move the payment processing code into a separate service to increase its reliability and availability, by reducing impact of more frequent changes in other services.
- move the unstable or changed frequently code to a separate service. Isolating issues in a service increases reliability and availability of other services and helps to narrow down the scope of the bugs. However the latter could be achieved in other ways: with proper component division, call logging and tracing etc. So it's just benefit but not a reason to move a component into a separate service.
- isolate components under high load so they don't affect performance and availability of other components. Example: component with load peak times (holidays, Friday, year start or end). If we place it into a separate service, other services that don't participate in a same workflow with a component with performance issues, are not impacted and still available.
- make smaller deployment unit with smaller startup time to react to the workload changes faster
In this stage we still keep connections to a single database. It works the same as for monolithic application, if we don't have many separate services:
- some database schema changes like column rename or removal for one service could break other services
- number of connections is still sufficient for several processes that use one database
What's the price of it? Trade-off analysis
Moving the component code into separate service comes with a price: local calls between components are replaced with timely remote calls. Having too many remote calls within one user scenario could increase the response time significantly.
If the primary business requirement for workflow is responsiveness, when the response time should be almost always within the specified time limit, we should try to decrease number of remove calls by replacing several remote calls to one service with one aggregated call that makes local calls within the service. If it's not enough to reach the acceptable response time within a workflow, consider keep or moving several components into one services to eliminate remote calls between them.
So there's no best option for every case: keeping components in one service is better sometimes, depending on our requirements and priorities.
Trade-off is a choice that has pros and cons, each of them could be significant or not depending on the case. So trade-off analysis is applying the requirements (context) to benefits and losses for each architecture decision we consider, and choose the option with the least worst calculated pros-and-cons cost.
There's no strict formula how to do this, but possible option is primary requirements are met first, then the difference between benefits and drawbacks numbers is maximized. More sophisticated formulas could include weights, higher for most significant requirements, lower for other.
Pitfall: remote synchronous call. Messaging.
Consider that service A calls service B synchronously for specific workflow. Then service B should be available, and the availability problem isn't solved: the request can't be completed without both services available. Another issue: service B should respond promptly depending on the service A call rate, or they both should have similar performance capabilities.
Are there ways to solve this? Possible option: service B responds later when it's available and able to do this without performance issues. It's achieved via asynchronous messaging:
- service A sends a data message to message broker without waiting the message processing result
- the message broker delivers the message to service B when it's available and can process it
- service B processes the message: makes appropriate data changes, sends messages to other services
If the service A has to take action when the service B has processed the message, then possible ways to achieve this:
- processing is done on the response message from service B
- makes additional synchronous requests to service B until it gets the positive response the message sent has been processed. It requires implementation of the message processed check, for example if the specific data has been updated
The problem is, the time of message processing by service B is not guaranteed (the maximum time is not limited), so the completion time for any option above is also not guaranteed.
There are two types of message brokers depending how many times a message is processed:
- one time: only one recipient is possible. Example: RabbitMQ queue server.
- many times: copies of a message could be delivered to several types of recipients. Can add message consumers independently from a producer, except the data format dependency. Example: Kafka server.
Example how to use many message handlers / consumers. The "Product is purchased" message is sent to Kafka, possible message consumers are:
- send customer email consumer
- company invoicing
- analytics events
- stock service consumer that tracks quantity of a product in stock, additionally the stock service sends a message to the supplier service to get more products if it's necessary.
Such approach allows to add many participant services into workflows without knowledge about each other, even linking them into processing chains. However it comes at cost as well: it's harder to understand how such systems work.
Going further: database split. Database per service.
We can make services less dependent with moving service data into a separate database. Let's look into a school web application separated into services:
- content service:
- question catalog, questions on different subjects: Math, Geography, Physics, Chemistry etc.
The are many types of questions: one choice, multiple choice, match the options, click on location. Example: locate Cairo on the map. - quizzes: set of questions on specific subject and topic. Example: Geography Class 5, Rivers in Europe
- question catalog, questions on different subjects: Math, Geography, Physics, Chemistry etc.
- teacher service:
- lists of classes and students in classes
- assign quiz to a student
- class quiz assignment result dashboard that shows students in the class and their scores on each assignment
- student service:
- list of quizzes assigned, with the due date
- quiz runner to start quiz assignment to shows questions and sends back the student answers and final score
All three services can work on one database:
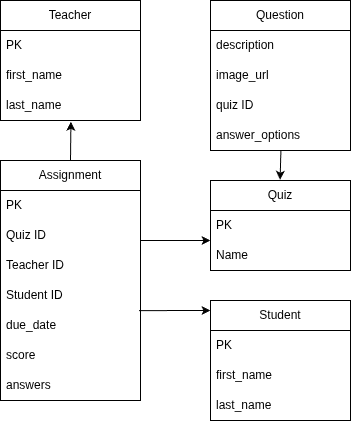
But each service is available till the shared database is available.
Imagine the situation: a lot of students use the system simultaneously to finish their assignments in time. Then the database slows down and makes a teacher service not available so they can't see the students progress or make a new assignment.
Scaling up the student service doesn't help, as the performance issues are causes by the relational database which can't be scaled up easily.
What's the option:
- having a separate database for the student service with the assignment data
- when a teacher assigns a quiz: a message with quiz ID and student ID list is sent. The message is delivered to the student service when it's available. Quiz assignment is created for the students In the student database
- when student starts a quiz: all the information is loaded from the student database without accessing the teacher service data so it doesn't impact its performance. Also it doesn't require the teacher service is available.
- when student finishes a quiz: the answers are sent via message to the teacher service and saved in the teacher assignment table
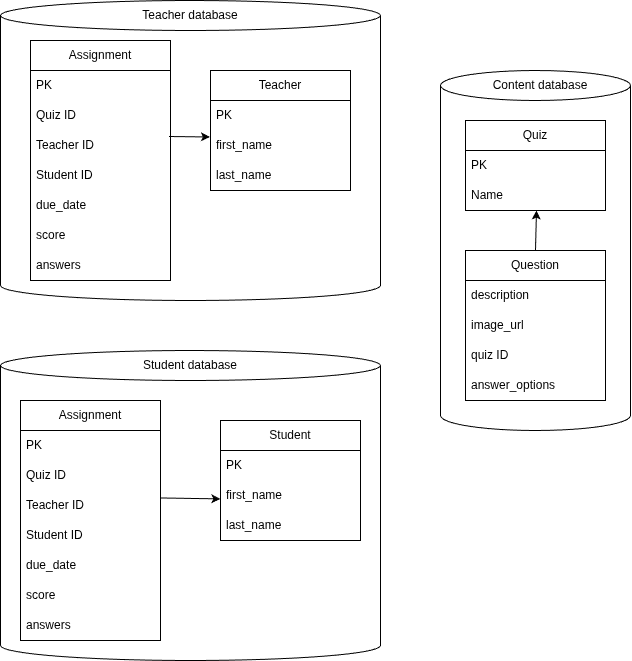
What's the trade-offs of database split:
- less reference integrity via foreign keys: can't have foreign keys between tables in different databases. So we have to drop the student ID column foreign key from the assignment table in the teacher database, and can't create foreign key to the teacher table from the student database. As well we drop foreign keys to the Quiz table if we move it to a separate database.
- not guaranteed response time when a student sees the assignment made and teacher gets the result. But for our system is acceptable that it's available in seconds or minutes instead real-time. there's no database transactions across all the databases so can't guarantee that the data is consistent (in sync) in all services in case of failures.
- data access from many services: the data can't be accessed directly in the database from other service. Other service should make remote call and data should be sent in a message. It could cause performance issues in case of many remote data requests.
Loading student list remote call takes much more time that loading them from the same database, but fortunately it could be made as one remote call to return all students from one class, or by ID list.
- data ownership for many services, if many services update the same data. As option, one service updates it in own database, other services request updates remotely via API. So the teacher assignment is updated via remote call to this service or via sending a message to it, instead direct database access.
In our application, consistency requirement is: the student quiz answers should be stored in the teacher service database as well. We can make the guaranteed message delivery to the teacher service by splitting it into two transactions in the student database:
- save the answers, save a student answers not delivered message into a separate table in the student database
- read not delivered answers message, send a message to the message broker, mark the message as delivered in the database
Conclusion
- modular application that consists from components with clear boundaries, solves a lot of issues: maintainability, partly reliability
- having separate services can increase reliability, availability and speed up delivery
- having too much services or remote calls between services could impact performance, data consistency and reliability
- trade-off analysis gives insights how to make better choices
References
- Fundamentals of Software Architecture: A Modern Engineering Approach, by Mark Richards, Neal Ford
- Software Architecture: The Hard Parts: Modern Trade-Off Analyses for Distributed Architectures, by Neal Ford, Mark Richards, Pramod Sadalage, Zhamak Dehghani